1. 거리-벡터 라우팅(Distance-Vector Routing)
거리-벡터 라우팅에서 제일 처음으로 각 노드가 만드는 것은 인접한 이웃들의 기초 정보를 이용하여 작성된 자신의 최소-비용 트리이다. 거리-벡터 라우팅에서 라우터는 자신이 가지고 있는 인터넷에 대한 정보가 불완전하더라도 자신이 알고 있는 네트워크 정보를 자신의 모든 이웃들에게 끊임없이 알려준다.
- 벨만-포드 방정식
벨만-포드 방정식은 거리-벡터 라우팅의 핵심아이디어로 이 방정식은 발신지에서 중계 노드 사이의 비용과 중계 노드와 목적지 노드까지 최소-비용으로 주어졌을 때 중계 노드(a, b, c, ...)를 통과하는 발신지 노드 x와 목적지 노드 y 사이의 경로에서 최소-비용(최소 거리)을 찾기 위해 사용한다.

- 거리-벡터
최소-비용 트리는 트리의 루트에서부터 모든 목적지까지 최소-비용 경로와 결합되어 있다. 이러한 경로는 트리를 구성하기 위해 함께 묶여 있다. 거리-벡터 라우팅은 이러한 경로들을 묶지 않고, 트리를 나타내는 일차원 배열을 이용하여 거리-벡터를 생성한다.

아래 그림은 네트워크에서 모든 거리-벡터를 나타낸다. 그러나 해당 노드가 부팅될 때 그림에서 나타낸 모든 벡터들이 동기화되어 작성되었음을 의미하는 것은 아니기 때문에 거리-벡터는 비 동기적으로 작성될 수 있다.

아래 그림은 각 갱신에 대한 모든 벡터 대신에 7개의 방정식을 보여준다. 그림은 어떠한 시간 동안 연이어 발생하는 2개의 비동기 이벤트를 보여준다. 처음 이벤트에서 노드 A는 자신의 벡터를 노드 B에게 전송한다. 노드 B는 비용 C = 2를 이용하여 노트 B의 벡터를 갱신한다. 두 번째 이벤트에서는 노드 E는 자신의 벡터를 노드 B에게 전송한다. 노드 B는 비용 C = 4를 사용하여 자신의 벡터를 갱신한다.

- 거리-벡터의 문제점
1. 무한대로의 카운트
거리-벡터 라우팅에서의 문제점은 비용 감소와 같은 좋은 소식은 빠르게 퍼지나 비용 증가와 같은 나쁜 소식은 천천히 퍼진다는 것이다. 라우팅 프로토콜이 잘 동작하기 위해서는 링크가 고장 나서 비용이 무한대로 바뀌었을 때 모든 다른 라우터들이 이를 즉시 인식할 수 있어야 하는데 거리-벡터 라우팅에서는 이에 시간이 소요된다. 고장 난 링크에 대한 비용이 모든 라우터에서 무한대로 기록되기까지 몇 차례의 갱신이 수행되어야 한다.
2. 두 노드 루프
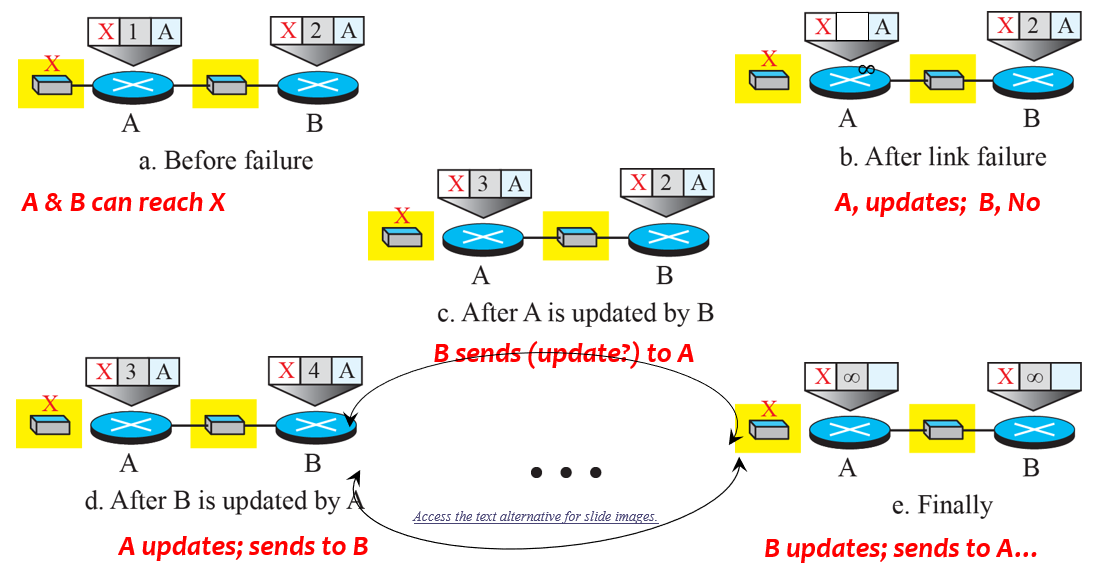
초기에 노드 A와 B는 노드 X에 도달하는 방법을 알고 있다. 그러나 갑자기 A와 X 사이의 링크가 실패했다고 하면 노드 A는 자신의 테이블을 변경한다. 만약 노드 A가 즉각적으로 B에게 테이블을 전송하면 문제가 없다. 그러나 만약 B가 라우팅 테이블을 A로부터 받기 전에 자신의 라우팅 테이블을 보내게 되면 시스템이 불안정해진다. 노드 A는 갱신을 수신하면 B가 X로 가는 길을 찾았다고 가정하고 즉각 자신의 라우팅 테이블을 갱신한다. A는 새로운 갱신을 B에게 보낸다. 이제 B는 A에 무슨 변화가 있다고 생각하고 자신의 라우팅 테이블을 변경한다. X에 도달하는 비용이 점점 증가하게 되어 최종적으로 무한대가 된다. 이런 종류의 불안정 문제를 위해 해결책이 제안되었다.
- 수평 분할
해결 방안 중 하나는 수평 분할(split horizon)이라고 불린다. 노드B는 A에게로 보내기 전에 라우팅 테이블에서 마지막 줄을 제거하게 된다. 이 경우 노드A는 X까지의 거리를 무한대로 유지하게 된다. 나중에 노드 A가 자신의 라우팅 테이블을 B에게 전송하면 노드 B도 자신의 라우팅 테이블을 수정하게 된다. 따라서 처음 갱신 이후 시스템은 안정적으로 되고 노드 A와 B 모드 X로의 경로가 도달 가능하지 않음을 알게 된다.
- 포이즌 리버스
노드B는 여전히 X에 대한 값을 광고하되 만약 정보의 송신자가 노드 A인 경우, 거리값을 무한대로 설정해서 이 값을 사용하지 말라고 경고한다.
2. 링크-상태 라우팅
이 방법은 인터넷에서 네트워크를 나타내는 링크(엣지)의 특성을 정의하기 위해 링크 상태를 사용한다. 더 낮은 비용을 가진 링크가 더 높은 비용을 가지고 있는 링크 보다 선호된다. 만약 링크의 비용이 무한대라면 이것은 링크가 존재하지 않거나 링크가 폐쇄되어 있음을 의미한다.
- 링크-상태 데이터베이스
모든 링크의 상태 집합을 링크-상태 데이터베이스(LSDB, Link-State Database)라 부른다. 전체 인터넷에 대해 단지 하나의 LSDB만 존재한다. LSDB의각 셀의 값은 대응하는 링크의 비용으로 결정된다.

플러딩(flooding)이라 불리는 과정을 통해 LSDB를 만들 수 있다. 네트워크 정보가 필요하지 않다. 노드에서 모든 인접 네트워크로 전송된 패킷 들어오는 링크를 제외한 모든 링크에서 들어오는 패킷 재전송 결국 다수의 복사본이 목적지에 도착할 것이다. 각 패킷에는 고유한 번호가 지정되어 중복 항목을 삭제할 수 있다. 노드는 네트워크 로드를 경계로 유지하기 위해 이미 전달된 패킷을 기억할 수 있다. 홉 카운트를 패킷에 포함할 수 있다: 일부 최대값으로 설정 > 카운터가 0일 때 삭제

- 최소-비용 트리의 형성
공유된 LSDB를 사용하여 최소비용 트리를 작성하기 위해서, 각 노드는 다익스트라(Dijkstra) 알고리즘을 사용해야만 한다. 이 반복적 알고리즘은 다음과 같은 단계를 사용한다.
- 노드는 하나의 노드를 사용하는 트리를 작성하기 위해 자기 자신을 트리의 루트로 선택하고, LSDB의 정보를 기반으로 하여 각 노드이 전체 비용을 계산한다.
- 노드는 트리에 속하지 않는 모든 노드들 중에서 루트와 가장 근접한 하나의 노드를 선택하고, 이것을 트리에 추가한다. 트리에 노드를 추가한 다음 경로가 변경되었기 때문에 트리에 속해 있지 않는 모든 트리의 비용은 갱신되어야 한다.
- 노드는 모든 노드가 트리에 추가될 때까지 두 번째 단계를 반복한다.

3. 경로-벡터 라우팅
Link-state(LS) 및 Distance-vector(DV) 라우팅은 모두 최소 비용 목표를 기반으로 합니다. 그러나 이 목표가 우선순위가 아닌 경우가 있다. 예를 들어, 보낸 사람이 패킷이 통과하지 못하도록 하려는 일부 라우터가 인터넷에 있다고 가정한다. LS와 DV라우팅이 적용된 최소-비용 목표는 발신자가 패킷이 지나가는 라우터에게 특정한 규칙을 적용시킬 수 없다. 이러한 요구에 대응하기 위해 경로 벡터(PV) 라우팅이라고 하는 세 번째 라우팅 알고리즘이 고안되었다.
- 스패닝 트리
경로-벡터 라우팅에서는 발신지에서 모든 목적지까지의 경로는 스패닝 트리에 의해 결정된다. 하지만 스패닝 트리는 최소-비용 트리가 아니다. 만약 목적지까지 하나 이상의 경로가 있다면, 발신지는 가장 최선의 규칙을 사용하는 경로를 선택할 수 있다. 일반 규칙 중 하나는 최소-비용과 비슷하게 방문 노드의 수를 최소화 시키는 것이다.

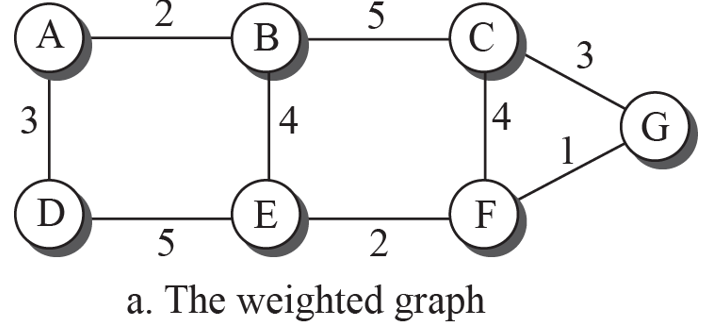
위 그림의 각 발신지는 고유의 규칙을 이용하는 스패닝 트리를 가지고 있따. A와 E로부터 선택된 스패닝 트리는 중계노드로 D를 거치지 않고 통신할 수 있다. 이와 유사하게 B로부터 선택된 스패닝 트리는 중계 노드로 C를 거치지 않고 통신할 수 있다.
- 스패닝트리의 생성
노드가 부팅될 때 이웃으로부터 얻게되는 정보를 기반으로 경로 벡터를 작성한다. 테이블들은 각 노드들이 부팅될 때 작성된다. 처음 경로 벡터를 작성 후에 각 노드들은 모든 경로를 자신의 인접 노드들에게 전송한다.
규칙은 다중 경로 중 가장 좋은(best) 경로를 선택하도록 정의된다.

'Study > Networking' 카테고리의 다른 글
| 9.1 전송층 서비스(TransportLayer Service) & 9.2 전송층 프로토콜 (2) | 2023.05.30 |
|---|---|
| 8.3 유니캐스트 라우팅 프로토콜 & 8.4 멀티캐스트 라우팅 (1) | 2023.04.16 |
| 7.5 IPv6 & 7.6 IPv4 to IPv6 (0) | 2023.04.14 |
| 7.4 IPv4 - (3) (0) | 2023.04.14 |
| 7.4 IPv4 - (2) (0) | 2023.04.13 |



